近日,智能车辆团队论文《Learning‐based tracking control of AUV: Mixed policy improvement and game‐based disturbance rejection》在CAAI Transactions on Intelligence Technology上发表。
专注于解决考虑扰动和输入约束的运载装备最优跟踪控制问题,针对有模型控制方法在复杂环境下模型难以精准建立的难题以及无模型控制方法训练效果不佳的缺陷,设计了一种基于零和博弈的鲁棒混合型ADP(Mixed ADP,MADP)方法。首先,基于系统状态与目标轨迹构建了一个误差状态增广系统,将原跟踪控制问题转化为镇定控制问题;然后,为避免不精确建模带来的模型与控制失配,以及纯数据驱动方法中训练不稳定的问题,本文在策略更新过程中引入了自适应调节因子,旨在平衡策略改进方向;而后,将含扰动的最优控制问题构造为零和博弈问题,在现有的评估执行框架中引入了与执行模块相博弈的扰动模块;接着从理论角度分析了基于值迭代的所提方法的收敛性;最后通过一个仿真案例验证了所提方法的有效性。
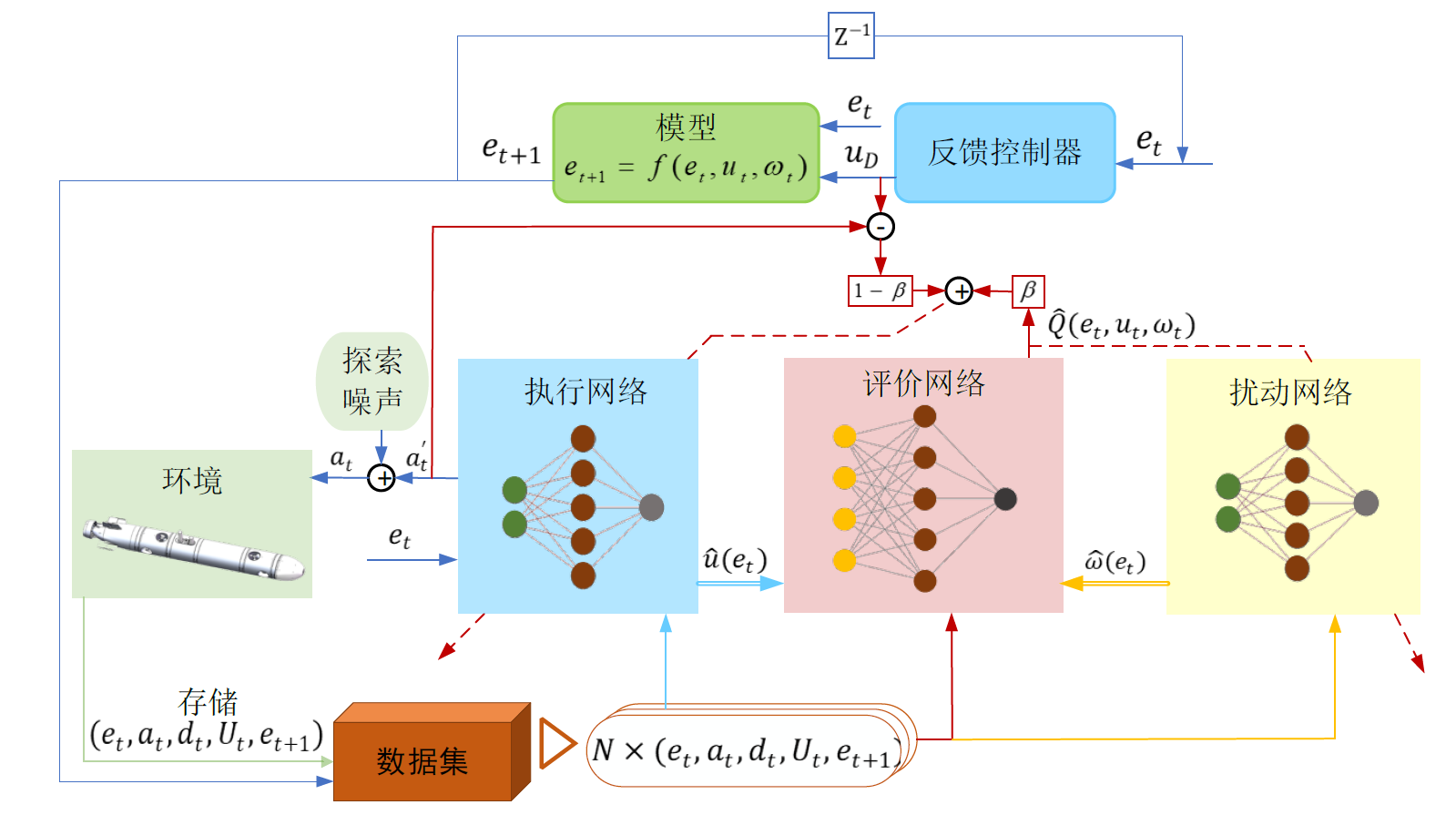
本文提出一种基于零和博弈的鲁棒混合型ADP(MADP)方法。本研究的主要贡献可归纳如下:
1)针对受干扰的AUV最优跟踪控制问题,提出了一种迭代ADP方案。该方法利用交互式数据和AUV动力学模型的先验知识,有效缓解了动力学模型不准带来的缺陷,且提高了ADP算法的训练速度。与基于模型的方法相比,所提MADP方案在最优性和跟踪精度方面均得到了提高。与数据驱动的方法相比,提出的MADP加快了最优策略的收敛速度,且提高了采样效率。
2)将考虑干扰的最优跟踪控制问题看作一个二人零和博弈问题,从而可以针对任意外部干扰制定最优控制策略。与传统方法在非合作博弈中,将扰动仅仅视为与迭代控制策略交互的附加策略不同,安全限制被始终考虑到扰动和控制策略的相互作用中。这确保在存扰情况下寻优时,可有效约束导致控制对象偏离安全区域的潜在情况。
3)基于价值迭代框架提出了一种新的训练方法,即统一了基于模型的控制和基于数据的ADP方案。通过在策略改进过程中引入自适应调节方程,有效平衡了基于模型的控制律和基于数据驱动的策略梯度对策略更的影响。基于推导的调节规则,本文分析了MADP算法的收敛性质,推导出每个网络学习率上界的充分条件。
论文作者列表:叶俊、高洪波、胡满江、边有钢、崔庆佳、秦晓辉、丁荣军
论文链接:https://ietresearch.onlinelibrary.wiley.com/doi/epdf/10.1049/cit2.12372


